Automatic intent classification
As manual classification of commit intents is time intensive an automated approach is needed.
We evaluate an automatic approach in a multi-class setting for our labels (other, perfective, corrective).
With a suitable automated approach, we can classify the rest of our data which enables us to include more data in our answers
what changes when developers increase quality.
We used the manual labeled data we created in this study to evaluate an automatic approach against a simple baseline.
Evaluation
We use 10-fold cross-validation to evaluate the models. To mitigate random effects when selecting the evaluation data for the seBERT model we run this loop 10 times. Each model therefore makes 100 predictions which are evaluated.
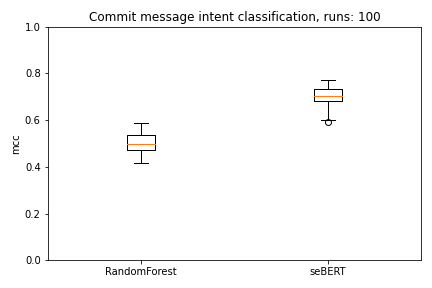
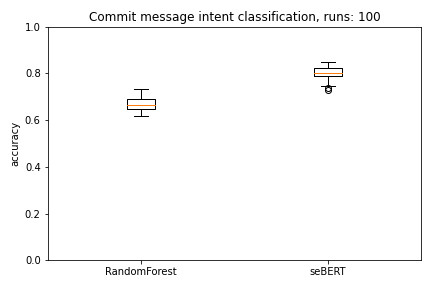
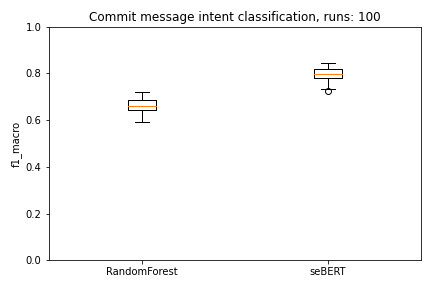
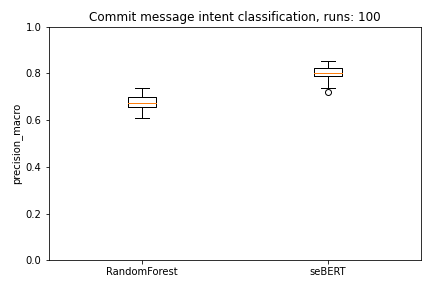
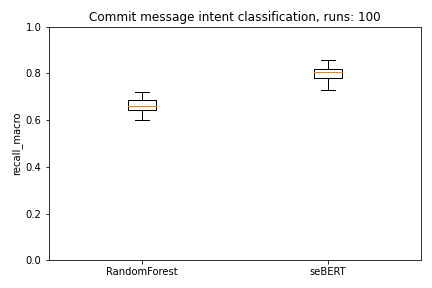
As we can directly see in the plots, seBERT has a good performance and outperforms the baseline RandomForest.
Moreover, with a median MCC of around 0.70 and F1 of 0.80 the perfomance is reasonably good to let the model predict the commit intent on the rest of the data.